De Big Data Revolutie van Schönberger en Cukier is vooral interessant door de talloze voorbeelden die erin staan beschreven. In dit artikel vat ik een paar van de mooiste casussen samen. Volgens de auteurs is de betekenis van Big Data kortgezegd dat de data volledig is (n=alles), in tegenstelling tot reguliere statistische steekproeven waarbij een representatief deel van de data wordt gebruikt. Het wordt dan niet met zo veel woorden gezegd, maar dit boek gaat over de praktijk van data mining op big data. Dat wil zeggen het vinden van verborgen verbanden binnen grote datasets. De Big Data Revolutie van Schönberger en Cukier is interessant als je wilt weten hoe Big Data wordt gebruikt vandaag de dag en wat hier voordelen en risico’s van kunnen zijn.
Amazon
Bij Amazon werden voorheen boekrecensenten ingezet om boeken op de webwinkel te beschrijven en catagoriseren. Aanbevelingen werden simpelweg op basis van deze catagorieën gedaan. Wanneer men bijvoorbeeld een boek over Polen kocht, kreeg men suggesties over boeken over Oost-Europa. In 1998 vroeg Amazon patent aan op een systeem waarbij voorkeuren door het systeem aan elkaar werden geassocieerd (gecorreleerd). Wanneer bijvoorbeeld bleek dat bezoekers die interesse hadden in boek X, ook interesse hadden in boek Y, werd boek Y als suggestie worden gegeven voor geïnteresseerden in boek X. Na implementatie van dit systeem bleken de verkoopcijfers vele malen beter met dit nieuwe systeem in vergelijking met aanbevelingen op basis van catagorisering. Uiteindelijk werd de afdeling redactie dan ook opgeheven.
Con Edison
De huisleverancier van electronische middelen in New York City, Con Edison werd ingezet om een oplossing te bieden voor het fenomeen van de exploderende putdeksels. Door de combinatie van oude bedrading en gassen uit het riool konden explosies ontstaan die de putdeksels meters hoog konden lanceren met alle gevaren van dien. Con Edison werkte samen met Colombia University om algoritmes te ontwikkelen die een voorspelling konden doen van waar de volgende putdekselincidenten zouden plaatsvinden. Hiervoor gebruikte men onder andere ruim 61.000 inspectierapporten en gegevens over hun kabels die dateerden tot 1880. Deze enorme hoeveelheid rommelige data diende eerst nog te worden opgeschoond, alhoewel dit natuurlijk maar tot op zekere hoogte mogelijk is. Op basis van deze data werd een lijst samengesteld van putdeksels met de hoogste risico’s voor incidenten. In de eerste instantie was 11% van alle incidenten te vinden in de bovenste 2% van de lijst (Ehrenberg, 2010). Bij een latere test in de Bronx in 2009 bleek dat 44% van de incidenten zich bevonden in de bovenste 10% van de lijst voor deze buurt (Mayer-Schönberger & Cukier, 2013).
Google Translate
De vertaalmachine van Google werkt met een techniek genaamd ‘Statistical Machine Translation’. Ook dit is een voorbeeld van Big Data / Data Mining. Door significante correlaties te zoeken binnen documenten en hun vertalingen (zoals VN rapporten en meertalige websites) kan een voorspelling worden gemaakt van welke vertaling waarschijnlijk correct is. Google Translate werkt met miljoenen van dergelijke documenten in tachtig verschillende talen. Google Translate is dus vooral een statistisch gebeuren. Wanneer je ‘auto’ intikt op deze online vertaalservice wordt in theorie simpelweg een berekening gemaakt, met als uitkomst dat ‘car’ met de grootste waarschijnlijkheid de juiste vertaling is. Een van de krachtige eigenschappen van deze statistische manier van vertalen is dat het contextgevoelig is en dus hele zinnen kan vertalen. Gezien de context van de zin hebben verschillende vertalingen de hoogste waarschijnlijkheid.
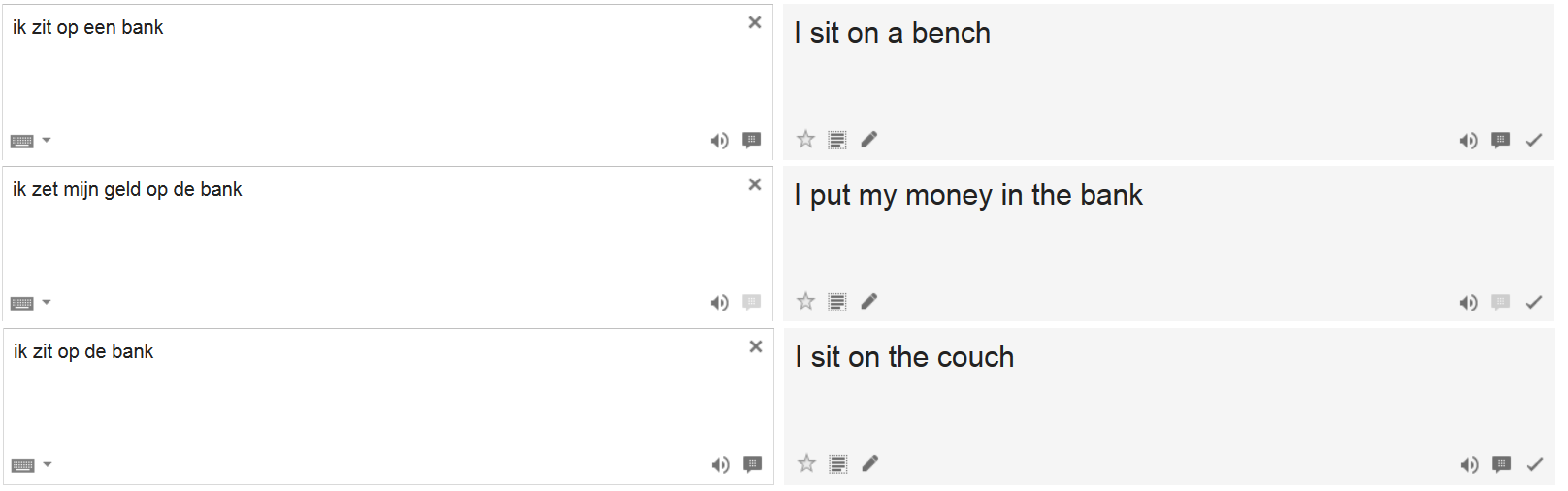
Zou Statistical Machine Translations ook fundamentele tekortkomingen hebben die grote, danwel onoverkomelijke obstakels vormen om ooit de menselijke vertaler te vervangen?
Target
Een beroemd voorbeeld inmiddels is een boze vader die naar een filliaal van Target (Amerikaanse detailhandel en webshop) ging om verhaal te halen over waarom zijn dochter kortingsbonnen voor baby-artikelen kreeg. Maar deze vader heeft later zijn excuses aangeboden aan de manager van dit filiaal omdat het bleek dat zijn dochter ook echt zwanger was. De dochter, wie zelf wel wist dat ze zwanger was voldeed schijnbaar aan een bepaald profiel dat op basis van grote hoeveelheden surfgeschiedenis is samengesteld. Vrouwen zouden schijnbaar in bepaalde stadia van zwangerschap behoefte hebben aan specifieke producten zoals geurloze lotion in de derde maand en een paar weken later voedingssupplementen zoals magnesium, calcium en zink.
Interessant om te vermelden is het aftreden van de topman van miljardenbedrijf Target, zes dagen voordat ik dit artikel schreef, zie Telegraaf: Topman Target stapt op na diefstal gegevens. Naar verluid zijn er door hackers persoons- en bankgegevens van miljoenen mensen buitgemaakt, ondanks het statement van de woordvoerder van Target: “Wij nemen onze verantwoordelijkheid voor het beschermen van de privacy van onze gasten zeer serieus.” (Geciteerd door Mayer-Schönberger & Cukier, 2013).
Overige voorbeelden
- Met 98% zekerheid de persoon kunnen herkennen aan de hand van gegevens over lichaamscontouren, houding en verdeling van gewicht op een zitvlak (mogelijk toekomstig toepasbaar als diefstalpreventie voor auto’s).
- In de techniek zijn voorspellingsanalyses (op basis van correlatie) al lang gemeengoed. Maar toch mooi om te vermelden is de casus van transporteur UPS. Doormiddel van voorspellingsanalyse wordt van 60.000 voertuiten de staat van diverse onderdelen in de gaten gehouden, wat het bedrijf miljoenen bespaart aan preventief onderhoud.
- Aan de hand van alle wedstrijduitslagen van ruim elf jaar werden In het Japanse Sumoworsten bepaalde patronen aangetoond die wezen op manipuleren van uitslagen. Zo zouden de zekere winnaars (die niets te verliezen hebben) spelers in veel gevallen laten winnen die anders gedegradeerd zouden worden. (Zou zo een analyse in veel andere sporten niet ook uitermate interessant kunnen zijn?)
- Op dit moment wordt aan het Institute of Technology van de universiteit van Ontario onderzoek gedaan naar hoe software die artsen helpt diagnoses te stellen voor te vroeg geboren baby’s. Aan de hand van data van bijvoorbeeld hartslag, ademhaling, temperatuur, bloeddruk en zuurstofgehalte kunnen veranderingen in de toestand van de baby worden gesignaleerd, die vierentwintig uur voordat de symptomen zichtbaar worden kunnen wijzen op een beginnende infectie.
Correlaties wijzen alleen op de samenkomst van x met y, wat echter niet hoeft te betekenen dat x de oorzaak is van y, zoals meerdere keren bevestigd in dit boek. Een aanzienlijke verschuiving die de ‘Big Data Revolutie’ zou veroorzaken is van de focus op oorzakelijkheid naar correlatie. We zouden tegen onze intuïtie moeten loslaten dat we overal de oorzaken van moeten weten en correlaties omarmen.
Echter is het weten van oorzaken toch meestal de sleutel is tot het daadwerkelijk oplossen van problemen, dus is het ook niet goed om door te slaan met deze correlaties. Wellicht is synergie mogelijk tussen deze twee vormen van onderzoek waarbij Big Data de voorzet geeft en doelpunten worden gemaakt met zuivere experimenten.
Referenties
Ehrenberg, R. (2010). Predicting the Next Deadly Manhole Explosion
http://www.wired.com/2010/07/manhole-explosions/
Geraadpleegd 11 mei 2014
De Telegraaf. (2014). Topman Target stapt op na diefstal gegevens
http://www.telegraaf.nl/digitaal/22588575/__Topman_Target_stapt_op_na_di...
Geraadpleegd 11 mei 2014
Mayer-Schönberger, V., & Cukier, K. (2013). De Big Data Revolutie; Hoe de data-explosie al onze vragen gaat beantwoorden
Amsterdam: Maven Publishing B.V.
Reactie toevoegen